睿帆科技獲數千萬融資,打造支持PB級處理的低代碼大數據中臺
據36氪報道,大數據技術與服務提供商睿帆科技在近兩年內已成功完成數千萬人民幣的融資。此輪融資將主要用于加強其核心產品的研發與市場拓展,特別是其自主研發的支持PB級數據處理的低代碼大數據中臺及數據處理服務。
隨著企業數字化轉型進入深水區,海量數據的實時處理與分析能力已成為企業提升運營效率、驅動智能決策的關鍵。傳統的大數據平臺往往存在開發周期長、技術門檻高、運維復雜等痛點,尤其對于非技術背景的業務人員而言,難以快速響應業務變化。睿帆科技瞄準這一市場缺口,致力于通過低代碼與高性能相結合的技術路徑,降低大數據應用開發與管理的復雜性。
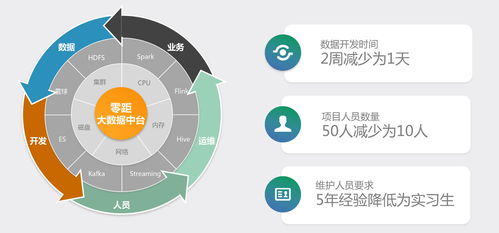
睿帆科技的核心產品是一個集數據集成、處理、存儲、分析與應用于一體的低代碼大數據中臺。其突出特點在于:
- PB級處理能力:平臺架構設計旨在應對超大規模數據集,能夠高效、穩定地處理PB級別的數據,滿足金融、電信、物聯網、互聯網等數據密集型行業的苛刻需求。
- 低代碼開發環境:平臺提供了可視化的拖拽式組件和豐富的預置模板,允許數據分析師和業務人員通過簡單的配置與組合,快速構建數據管道、開發數據分析應用,極大縮短了從數據到價值的實現路徑,提升了業務敏捷性。
- 一體化數據服務:該中臺不僅提供強大的底層數據處理引擎,還封裝了數據治理、數據資產管理和數據服務API化等上層能力,幫助企業構建統一、規范、可復用的數據資產體系,實現數據驅動的精細化運營。
此次獲得的數千萬人民幣融資,體現了資本市場對大數據基礎設施賽道,尤其是對能夠降低技術應用門檻、提升數據普惠能力的技術方案的看好。睿帆科技表示,資金將主要用于三個方面:一是持續加大在分布式計算、實時流處理、數據湖倉一體等底層技術上的研發投入,鞏固其在高性能數據處理方面的技術壁壘;二是進一步優化和豐富低代碼開發平臺的功能與體驗,擴大其在金融風控、智慧城市、工業互聯網等具體場景的解決方案庫;三是加強銷售體系與生態合作建設,加速市場布局。
業內分析認為,低代碼與大數據技術的融合正成為重要趨勢。睿帆科技將企業級數據處理能力與易用性相結合的產品思路,有望幫助更多企業,特別是中型企業和傳統行業客戶,跨越技術鴻溝,釋放數據潛能。在數字經濟浪潮下,此類專注于提升數據基礎設施效率和易用性的創新企業,其市場前景與成長空間值得期待。
如若轉載,請注明出處:http://www.nsfun.cn/product/50.html
更新時間:2026-03-15 01:57:26